前言
这节课的主要目的是介绍有限自动机模型,但是我们要先完成字母表、字符串和语言与可数性概念的讨论。
知识点
可数性和语言
上次我们讨论了一些语言的例子,并且思考过哪些语言是否有限。现在我们想一想语言背景下的可数性概念。
语言是可数的
我们以下面的命题开始。
命题2.1. 对于任意字母表$\Sigma$,语言$\Sigma^{*}$是可数的。
为了方便,我们主要关注对于二进制字母表$\Sigma=\{0,1\}$,如果证明这个命题;这个论证也很容易泛化成别的字母表。为了证明$\Sigma^{*}$是可数的,需要定义一个满射函数
事实上,从字符串的字典式排序出发,我们很容易得到一个以上形式的单射且满射的函数$f$。我们通过字符串长度来排序,然后对同等长度的字符串使用“字典”排序。$\Sigma^{*}$的字典式排序如下:
根据这个顺序我们可以定义一个满足形式的函数$f$,将$f(n)$设置为$\Sigma^{*}$的字典式序列中的第n个字符串,从0开始。这样,我们有
等等。有一个精确的计算$f(n)$的方法是将$n+1$写成二进制形式,然后丢掉最高位的1。
不难看出我们刚定义的函数$f$是满射的;每个二进制字符串都会作为函数$f$一个输出值。因此也就是说$\Sigma^{*}$是可数的。$f$也是一个单射函数。
我们很容易将这个论证泛化到其他的字母表。首先要做的事是决定这个字母表符号的顺序。对于二进制字母表,我们所接受的符号顺序是:先0,后1。如果我们使用其他的字母表,比如$\Gamma=\{\Game,\flat,\natural,\sharp\}$,排序的规则可能不太明显,但是只要我们选择一种或者保持不变就行。一旦我们确定了已知字母表$\Gamma$的排序,$\Gamma^{*}$的字典式排序就和我们上面做的一样了,使用字母表的顺序来决定“字典”顺序。根据得出的字典是排序,我们得到了一个单射且满射的函数$f:\mathbb{N}\rightarrow \Gamma^{*}$。
说明2.2. 关于术语“字典式排序”有一个简短的说明,有人用这个术语来表示一些不同的东西:根据长度而不是首字母的字典顺序。然后他们使用类似字典式排序来知道我们已知的字典式排序;这里完全没有必要担心这种矛盾。在科学和数学领域上有很多人们在术语上意见不一致的案例。重要的是每个人在使用时都清楚这个术语的含义。记住这一点,在本课程中字典式排序的意思就是字符串先按长度排序,等长的字符串再按“字典”顺序排列。
对于任意字母表$\Sigma$,从事实上来看语言$\Sigma^{*}$是可数的,而且每个$A\subseteq \Sigma^{*}$也是可数的。这是因为每个可数集合的子集也是可数的。
基于任意字母表的所有语言的集合是不可数的
接下来我们讨论基于一个已知字母表的所有语言的集合。如果$\Sigma$是一个字母表,让$A$表示基于$\Sigma$的语言,也可以说$A$是$\Sigma^{*}$的子集,而且$\Sigma^{*}$的子集也就是$\Sigma^{*}$的幂集中的元素。因此对于任意字母表$\Sigma$,以下三个声明是相等的:
- $A$是基于字母表$\Sigma$的一种语言。
- $A\subseteq \Sigma^{*}$。
- $A\in \mathcal{P}(\Sigma^{*})$。
对于任意字母表$\Sigma$,我们观察到每个语言$A\subseteq \Sigma^{*}$都是可数的,自然接下来就会问到是否所有基于$\Sigma$的语言集合是可数的。答案是否定的。
命题2.3. 已知一个字母表$\Sigma$,集合$\mathcal{P}(\Sigma^{*})$是不可数的。
为了证明这个命题,我们不需要重复$\mathcal{P}(\mathbb{N})$的对角化论证。相反,我们可以简单地将那个定理和和这个事实,存在一个从$\mathbb{N}$到$\Sigma^{*}$的单射且满射的函数,联系起来。
详细一点,已知
是一个单射且满射的函数,正如我们之前得自于$\Sigma^{*}$的字典式排序的那个函数。打个比方,我们可以如下将这个函数扩展到$\mathbb{N}$和$\Sigma^{*}$的幂集。已知
是一个函数,定义为
对于所有$A\in \mathbb{N}$。用文字表达就是函数$g$简单地将$f$使用在了$\mathbb{N}$的子集的每个元素上。不难看出$g$是单射且满射的;我们可以直接使用$f$的反函数来表示$g$的反函数,如下:
对于每个$B\subseteq \Sigma^{*}$。
现在,因为存在一个形如$g:\mathcal{P}(\mathbb{N})\rightarrow \mathcal{P}(\Sigma^{*})$的单射且满射的函数,我们得出$\mathcal{P}(\mathbb{N})$和$\mathcal{P}(\Sigma^{*})$是“数量相同”的。因为$\mathcal{P}(\mathbb{N})$是不可数的,所以$\mathcal{P}(\Sigma^{*})$也是。为了让表述更正式,有人可能会相反地假设$\mathcal{P}(\Sigma^{*})$是可数的,也就是说存在一个满射函数,像这样
使用$g$的反函数来改造一下上面这个函数,我们得到另一个满射函数
就我们所知这是矛盾的,因为$\mathcal{P}(\mathbb{N})$是不可数的。
确定性有限自动机
我们要讨论的第一个计算模型叫作确定性有限自动机模型。你应该早就学过有限自动机了,所以我们没必要从最简单的地方开始了 — 但是当然我们还是需要一个正式定义来进行数学计算。
当你思考确定性有限自动机模型时,请记住以下两点:
- 它的定义是基于集合的(还有函数,可以用集合属于来正式表达,你也可能在离散数学中学过了)。这并不奇怪:集合理论是很多数学研究的基础,而且我们下定义的时候很自然就会想到集合。
- 尽管确定性有限自动机在计算方面并不是很强大,但这个模型很重要,而且它仅仅是个开始。别看他好像是个弱小无用的模型;在这个阶段,我们并没有视图为通用计算机建模,而有限自动机的概念也绝非无用。
定义2.4. 一个确定性有限自动机(或者简称DFA)是一个5-元组
$Q$是一个有限非空集合(其中我们元素称为状态),$\Sigma$是一个字母表,$\delta$是一个函数(称作转移函数),形式为
$q_0\in Q$是一个状态(称作初始状态),以及$F\subseteq Q$是一个状态子集(其中所有的元素我们称为接受状态)。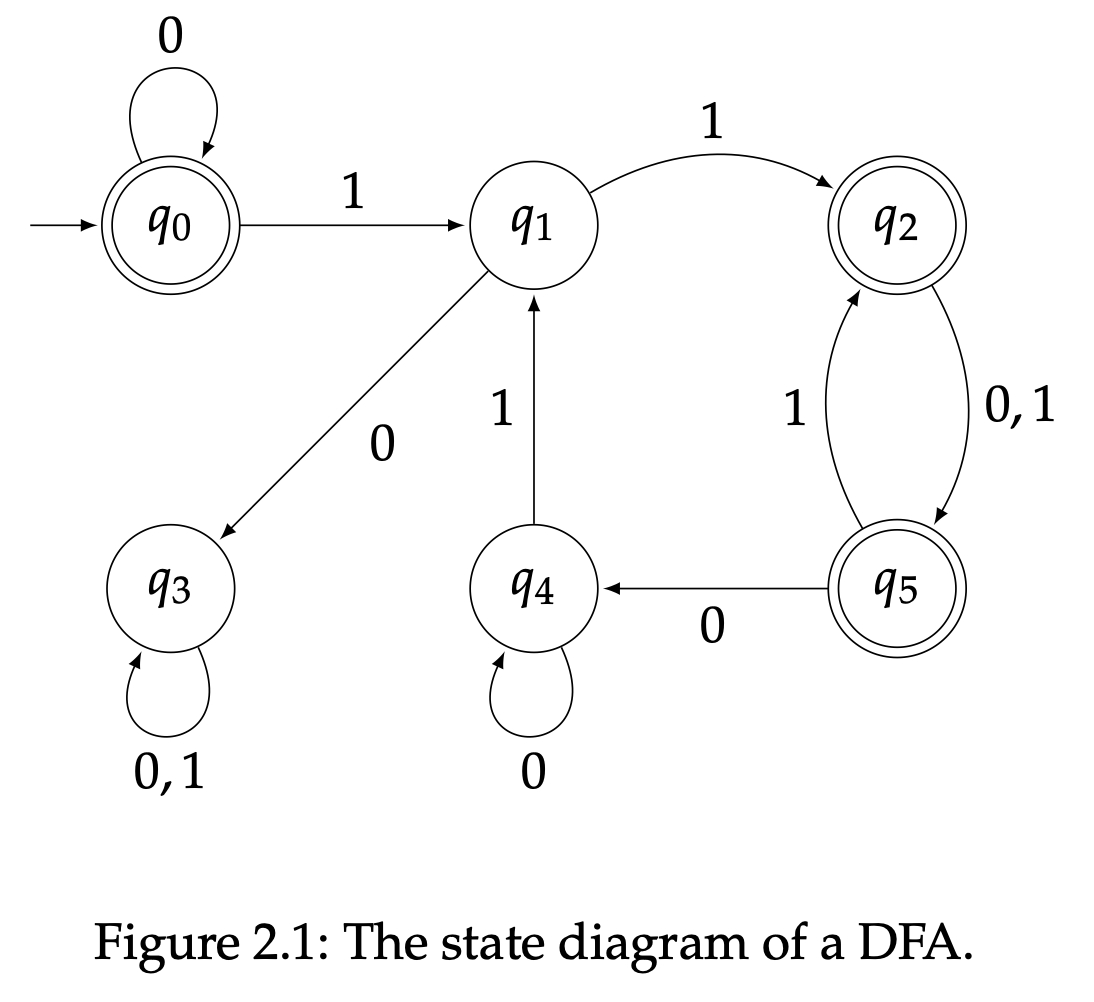
状态图
使用状态图来表示DFA是和常见的,正如图2.1所示。状态图表达了DFA正式定义中的五个部分:
- 圆圈表示状态。
- 带标签的箭头表示字母表。
- 箭头和与之相连的圆圈表示转移函数。
- 后方没有圆圈的箭头指向的初始状态。
- 双圆圈表示接受状态。
比如对于状态图2.1,它的状态集合是
字母表示
初始状态是$q_0$,接受状态集合是
转移函数$\delta:Q\times\Sigma\rightarrow Q$如下:
为了让一个状态图对应上一个DFA,更具体的说为了确定一个有效的转移函数,对于每个状态和每个符号,必须存在标有这个符号的一个箭头从这个状态离开。注意当一个箭头标有多个符号时,比如图2.1中有个箭头标有“0,1”,这应该被理解为存在多个箭头,每个都标有一个符号;使用同一个箭头表示多个转换,只是为了让图看起来更简洁。
DFA计算
你可能已经知道对于一个DFA $M=(Q,\Sigma,\delta,q_0,F)$拒绝或者接受一个输入字符串$w\in \Sigma^{*}$是什么意思,从定义上是可以猜出来的。可以简单地用语言来描述,特别是当我们打算用状态图的时候:我们从初始状态开始,根据$w$的符号进行状态转移,我们接受结果当且仅当我们结束在一个接受状态上(相反我们就拒绝)。
这些都是有意义的,但是考虑它是如何正式表达的还是有用的。也就是说,我们如何用精确地定义DFA接受或拒绝给定字符串的数学术语?特别是,像“进行转移”和“结束在一个接受状态”可以用更精确的数学概念替代。
这里有一种更正式地定义接受和拒绝的方式。也要注意这个定义集中在集合和函数。
定义2.5. $M=(Q,\Sigma,\delta,q_0,F)$是一个DFA,$w\in \Sigma^{*}$是一个字符串。这个DFA $M$接受字符串$w$,如果以下条件中的一个得到满足:
- $w=\varepsilon$和$q_0\in F$。
- 对于任意正整数n和符号$a_1,…,a_n\in \Sigma$有$w=a_1\cdot\cdot\cdot a_n$,存在状态$r_0,…,r_n\in Q$,使得对于所有$k\in \{0,…,n-1\}$有$r_0=q_0、r_n\in F$和$r_{k+1}=\delta(r_k,a_{k+1})$。
如果$M$不接受$w$,那么$M$就拒绝$w$。
用文字描述,接受的正式定义就是存在一个状态序列$r_0,…,r_n$使得第一个状态是初始状态,最后一个状态是接受状态,并且序列中的每个状态都是由前一个状态和从输入中读取的对应符号决定的,就像转移函数的描述:如果我们处于状态$q$,读取符号$a$,新的状态就是$p=\delta(q,a)$。定义条件中的第一条用于处理空字符串这种特殊情况。
很自然能想到为什么比起可读定义我们更喜欢正式定义。当然,可读定义用来解释DFA的概念是很有效的,但是正式定义的优点在于它将接受这个概念转化成了基本的关于集合和函数的数学表述。并且它也相当简洁和精确,对于DFA接受和拒绝的含义没有什么含糊的地方。
有时候定义一个新函数
会很有帮助,它基于给定的转移函数$\delta:Q\times \Sigma\rightarrow Q$,存在如下递归方法:
- 对于每个$q\in Q$有$\delta^{*}(q,\varepsilon)=q$,以及
- 对于所有$q\in Q、a\in\Sigma$和$w\in\Sigma^{*}$有$\delta^{*}(q,wa)=\delta^{*}(\delta^{*}(q,w),a)$
直观上说,如果你从状态$q$开始,根据字符串$w$进行转换,$\delta^{*}(q,w)$就是你结束的状态。
DFA $M=(Q,\Sigma,\delta,q_0,F)$接受字符串$w\in\Sigma^{*}$当且仅当$\delta^{*}(q_0,w)\in F$。有一种自然的方法来正式讨论这种情况,但是我们并不会具体去讲,是通过对$w$的长度归纳证明$\delta^{*}(q,w)=q$当且仅当下面两个两件有一个得到满足:
- $w=\varepsilon$并且$p=q$。
- 对于一个正整数$n$有$w=a_1,\cdot\cdot\cdot,a_n$,并且符号$a_1,…,a_n\in\Sigma$,存在状态$r_0,…,r_n\in Q$使得对于所有$k\in\{0,…,n-1\}$有$r_0=q、r_n=p$和$r_{k+1}=\delta(r_k,a_{k+1})$。
只要这个充要条件被证明,那么表述$\delta^{*}(q_0,w)\in F$和$M$接受$w$就是等价的。
注意2.6. 到目前为止我们没有证明过本课程中提出的表述。如果我们去证明,那将是很拖沓的,甚至我们会不停的回顾,感觉是不是有哪些地方还不够正式。如果我们坚持越来越正式地证明每件事,原则上我们会将每个数学声明约化到公理集合论 — 但那时我们一学期的课程只能附带一点点关于计算材料,而且可能会包含你期望那么多会在汇编语言编写的复杂的未测试的程序中的错误。
自然地我们不会这么做,但我们是不是会讨论证明的本质,如果我们有时间的话怎么去证明,某些高级的表述和论证如何被简化成更节本和具体的步骤,导向可以被计算机验证的完整形式的证明的一般方向。此时如果你还没确定一个证明的结构,或者在你的证明中你应该瞄准那些细节和正式,别担心 — 理清这些问题是本课程的主要目标之一。
被DFA识别的语言和正则语言
假设$M=(Q,\Sigma,\delta,q_0,F)$是一个DFA。那么我们会想到被$M$所接受的所有字符串的集合。这个语言被记作$L(M)$,所以
我们这是一个被$M$识别的语言。认清这是一个单一的定义明确的语言,精确包含了被$M$包含所接受的那些字符串以及不包含任何被$M$所拒绝的字符串,是很重要的。
比如,这里有一个基于二进制字母表$\Sigma=\{0,1\}$的简单DFA:
如果我们成这个是DFA $M$,那么被$M$所识别的语言很容易描述;那就是
这是因为$M$接受所有$\Sigma^{*}$中的字符串。现在,如果我们考虑另一个不同的基于$\Sigma$的语言,比如
那么当然$M$接受$A$中的所有字符串。然而$M$也接受属于$A$的字符串,所以$A$不是一个能被$M$所识别的语言。
我们还有一个定义,他介绍了一些重要的术语。
定义2.7. $\Simga$是一个字母表,$A\subseteq\Sigma^{*}$是基于$\Sigma$的一种语言。语言$A$是正则的当且仅当存在一个DFA $M$使得$A=L(M)$。
目前为止我们还没见过多少DFA,所以我们没有正则语言的例子来探讨,但是我们往后会见到足够多的DFA。
结束本节课之前,先来看一个问题。
问题1. 对于一个已知的字母表$\Sigma$,基于字母表$\Sigma$的正则语言的数量是否可数?
答案是“可数”。原因是基于任意字母表$\Sigma$的DFA的数量是可数的,而且我们可以将这个事实与一个观测结果联系,有一个将每个DFA映射到它所识别的正则语言的函数,根据定义,它是满射函数。
当我们说到DFA可数的时候,我们确实应该更精确一点。特别是,如果两个DFA除了状态取名之外都相同,我们认为它们没有不同。这是有原因的,因为我们给状态取的名字并不影响DFA识别语言 — 对于某个正整数$m$我们可能会假设DFA的状态集合$Q=\{q_0,…,q_{m-1}\}$。事实上,人们通常在画状态图时不会担心状态的名称,因为状态名称和DFA的运行方式无关。
为了弄清基于一个已知字母表$\Sigma$的DFA数量是可数的,我们使用类似于证明有理数集合$\mathbb{Q}$可数的策略。首先假设只有一种状态$Q=\{q_0\}$。基于只有一个状态的字母表$\Sigma$的DFA数量是有限的。(事实上只有两个,一个中$q_0$是接受状态,另一个中$q_0$是拒绝状态)现在考虑基于两个状态:$Q=\{q_0,q_1\}$的所有DFA的集合。DFA的数量也是有限的。像这样继续下去,对于任意正整数$m$,基于有$m$个状态的字母表$\Sigma$的DFA数量都是有限的。有$m$个状态的DFA数量呈现$m$的指数级增长,但目前这并不重要 — 我们只需要知道这个数量是有限的。如果你用某种方式列出DFA的有限列表,然后将这些列表穿起来,开始时1个状态的DFA,接着是2个状态的DFA,以此类推,你会得到一个包含了每个DFA的单一列表。从这个列表你能获得一个从$\mathbb{N}$到基于$\Sigma$的所有DFA集合的满射函数,使用的方式和我们前面证明有理数集合可数的类似。
因为语言$A\subseteq\Sigma^{*}$是不可数的,而且只有正则语言$A\subseteq\Sigma^{*}$才是可数的,我们立刻就得出结论:某些语言是非正则的。这只是一个存在证明,它并没有指明那些语言非正则 — 它只是告诉我们非正则语言是存在的。后面我们会讲到允许我们得出确定非正则语言的方法。